Queueing in Mendix Can Be a Good Thing

Queueing is frequently viewed as a time-waster, whether you are in a queue for the bus/tram/train home or queueing to get your lunch, or you are waiting on hold for someone in Customer Services to pick up your call from the phone queue at <enter your favorite retailer/supplier here>.
In a Mendix app, most actions are single-threaded so, for example, the action you define will start at the beginning and end at the end and in between will follow the operations you specify in the order that you specify. This keeps things nice and simple as you don’t need to worry too much about whether or not the operations you define will happen as you expect and if you have dependencies inside your action you can see clearly what they are.

On the other hand, queues can be good for your app because they can be used to spread the execution of a process across multiple threads and nodes. If you have a particular piece of work to get done, queues can help you out by allowing you to do different parts of the job concurrently, and overall, the process takes less time. So how can you do that?
This is the third in a series of blog posts about efficiency in Mendix apps. In the first of the series (Health and Efficiency in Mendix), I highlighted some of the simple ways that you might improve the efficiency of your low-code, and in the second (In Mendix how long is a String?), I showed how the use of Java actions can help with performance in tight corners. This time I want to illustrate how Mendix Task Queues may be used to make your app more efficient.
Task Queues
Mendix Task Queues were introduced in Mendix 9 as a modern replacement for the Process Queue marketplace module, and their features are well documented. In this post, I shall take a particular, simple use case and show how a Task Queue can be used to significantly cut the elapsed time taken to perform the process required.
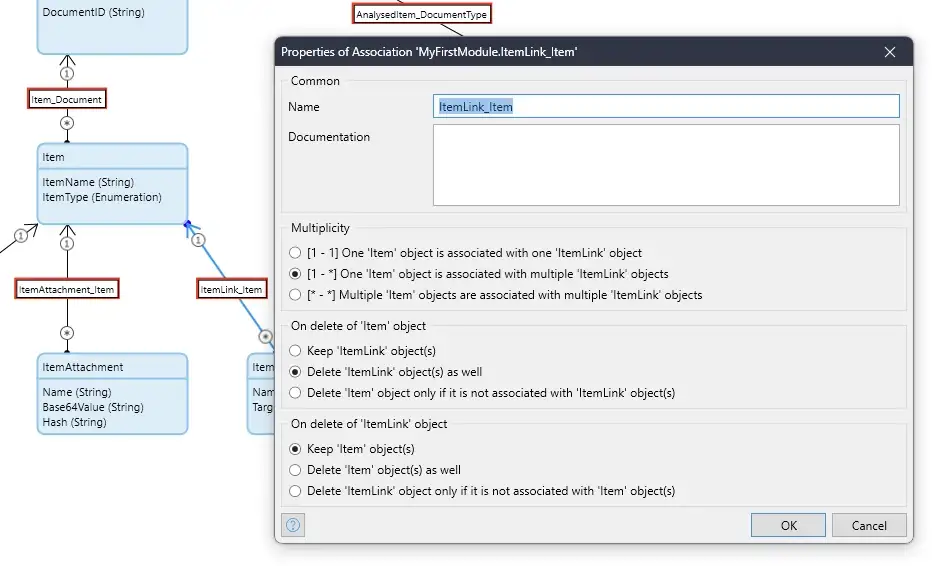
There is detailed documentation on the Task Queues Page that covers what you can do with Task Queues, and how to do it, including the newer features such as the automatic retrying of failed tasks and the scheduling of tasks to start to execute at a specific time. One important point to remember is that you have to be careful not to have dependencies between the ‘sub-tasks’ in your process unless you manage this yourself — the example use case shown here has simple dependencies and I have engineered a way to control that.
A large delete

My app is used to pull data from defined external data sources when the user requests it. That data is subjected to some simple analysis so that the user can make decisions about how the data should be used. At the point when the user is satisfied and has completed the job in hand, the data needs to be deleted.
A test app has been put together to illustrate how a Task Queue can accelerate the deletion process: GitHub – Adrian-Preston/QueueingCanBeAGoodThing
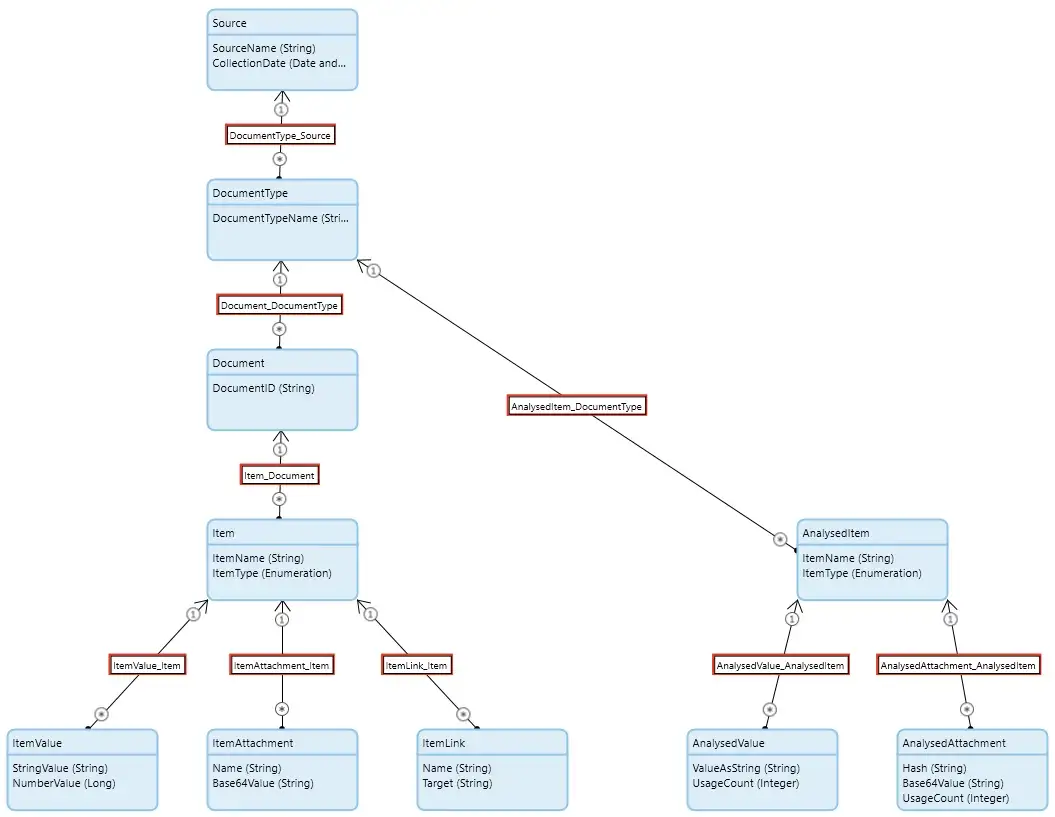
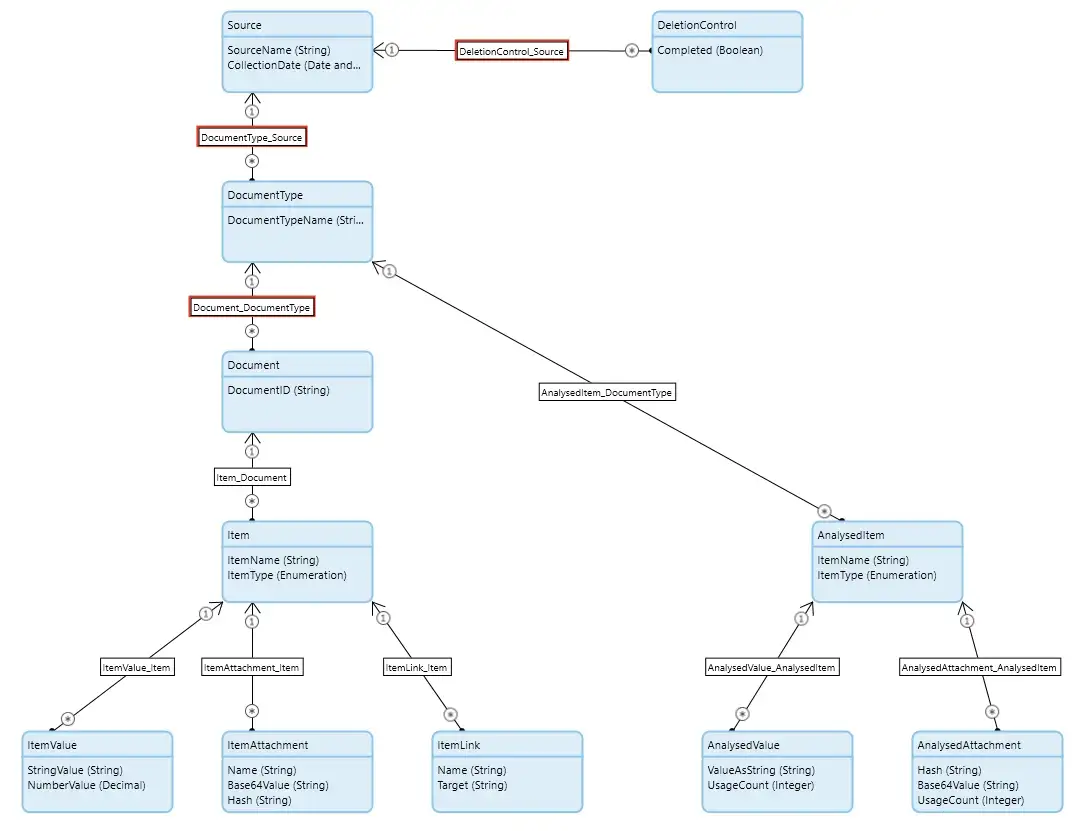
In the initial setup, the domain model has been configured for auto-deletion, so that deleting the Source object will automatically cascade down the tree deleting all the associated objects (highlighted by the association boxes in the domain model being bordered with red). This is a safe option as it will prevent ‘orphaned’ objects from being left behind and it also means that the developer can just delete the Source and everything else will follow. However, being a single-threaded operation, this can take some time if there is a lot of data in the tree.
As this is a relatively simple domain model, it’s pretty easy to see that we could safely delete objects for certain Entities concurrently. So ItemValue, ItemAttachment, ItemLink, AnalysedValue, and AnalysedAttachment (Set One) for a particular Source are safe to delete at the same time. Similarly, Item and AnalysedItem (Set Two) can be deleted concurrently, but only after the records in Set One have all been deleted. Finally, Source, DocumentType, and Document will have to be deleted in the correct order after Set One and Set Two have been deleted. These are the dependencies I mentioned earlier.
So how can this be done?
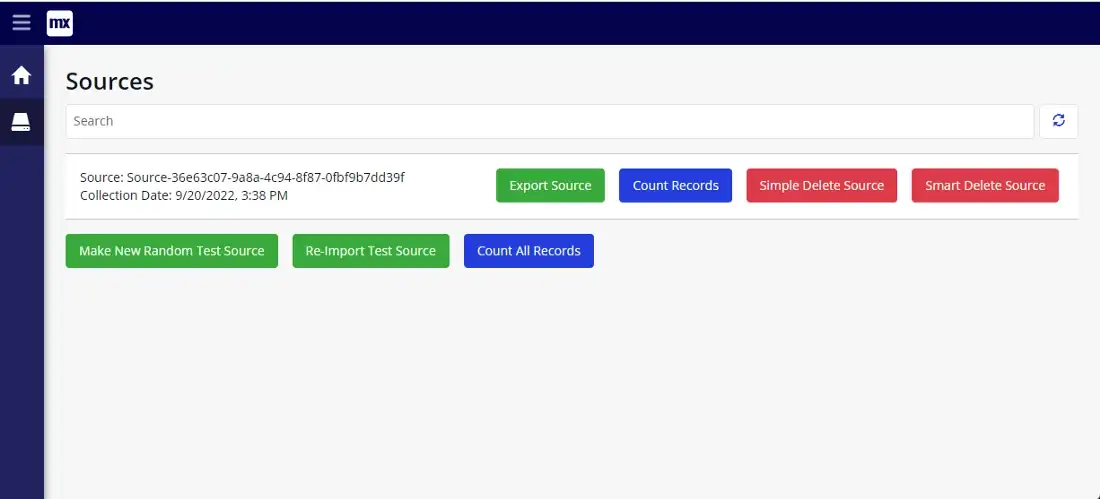
On the app UI, there is a page that lists the Sources which are currently loaded. From there the user identifies the Source to be deleted and hits the ‘Smart Delete Source’ button on that row.
This calls a nanoflow called ‘ACT_SmartDeletion’, which has two main tasks: firstly to start the deletion process off in the background; and secondly to wait for the Source record to disappear from the database indicating the task is complete.
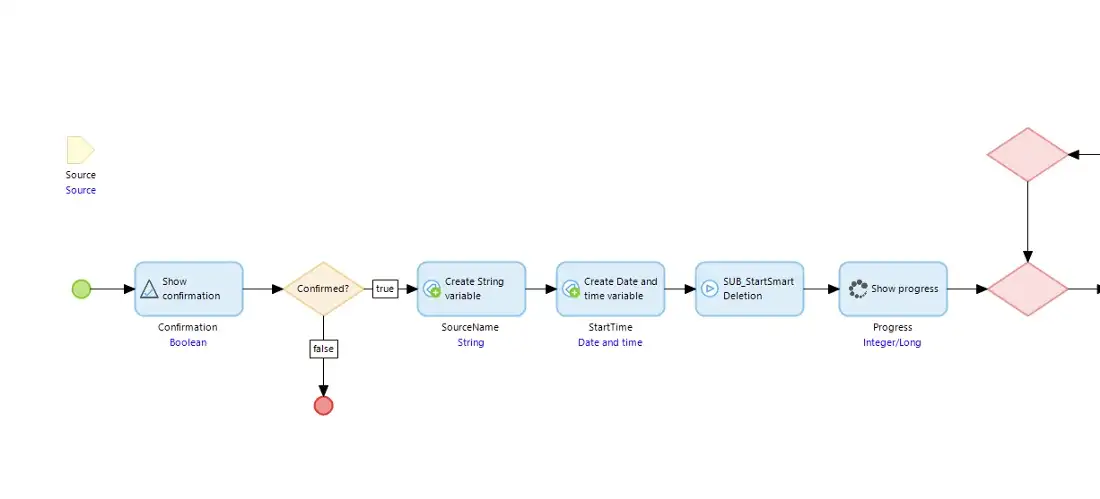
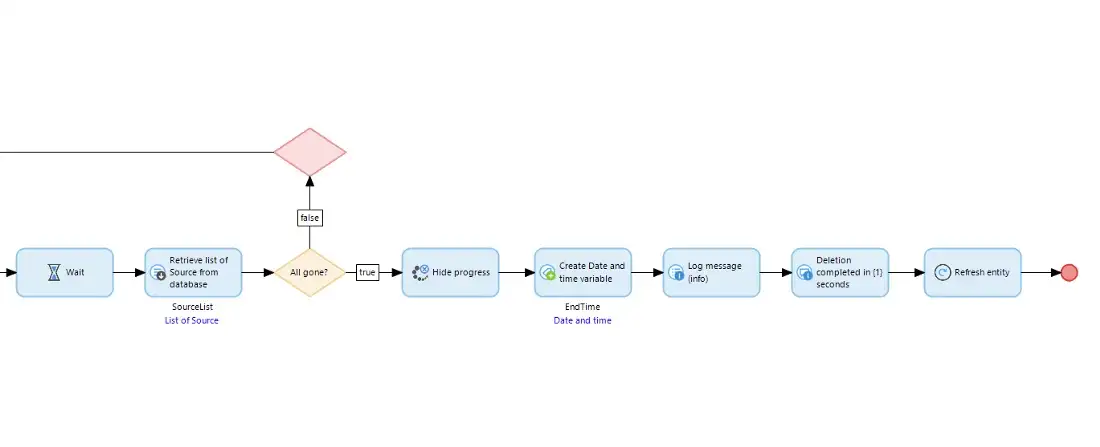
The nanoflow calls a microflow called ‘SUB_StartSmartDeletion’, which calls a sub-microflow for each entity type in Set One but these are each called by putting them into a Task Queue which means they are not executed directly, but rather just queued up so they run in the background. We also create a special DeletionControl object for each of the sub-microflows to receive — more on this below. When this microflow is finished then it returns to the nanoflow.
The nanoflow then enters a loop to see if the Source record is still there in the database, and while it is there the nanoflow pauses a short time and then checks again. When the Source record is no longer in the database the nanoflow tells the user and completes.
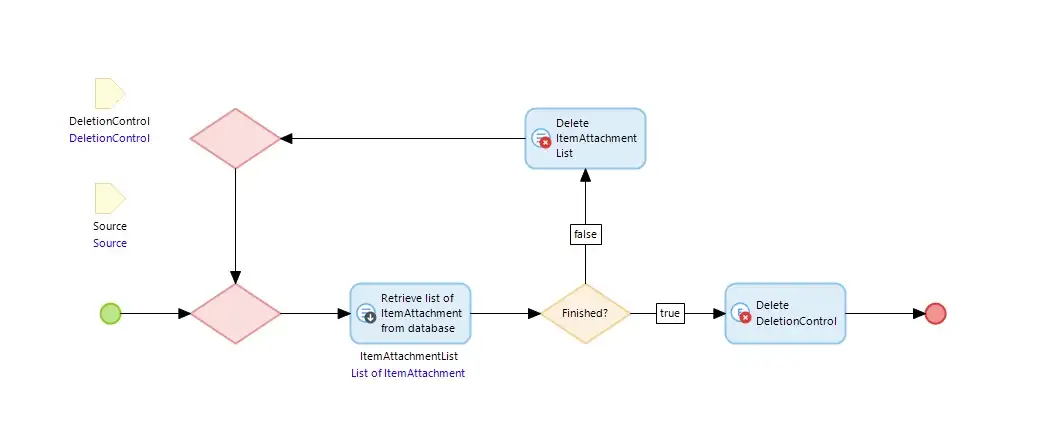
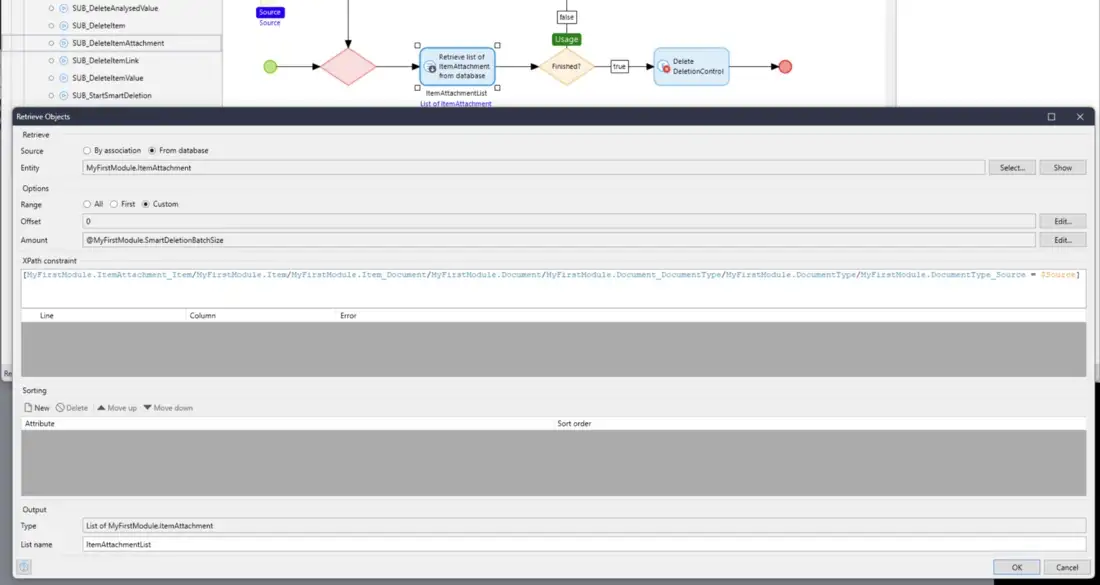
Each of the five sub-microflows is the same (except for one with some extra code). The sub-microflow deletes all the records for the Source of a particular type of Entity and then finally delete the DeletionControl object that was given above.
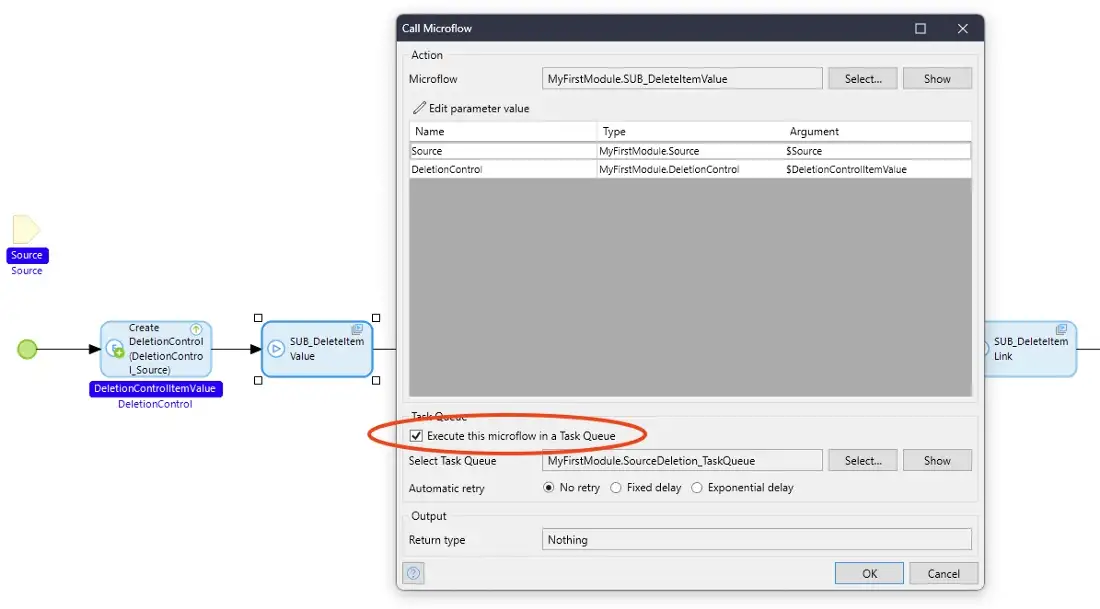
The additional code in ‘SUB_DeleteItemValue’ waits until all of Set One is completed (by checking for all the DeletionControl objects having been deleted) and then it starts off sub-microflows in the same Task Queue to run the deletion of the Entities in Set Two, so when Set One is completed Set Two deletion is automatically started using the same mechanism.
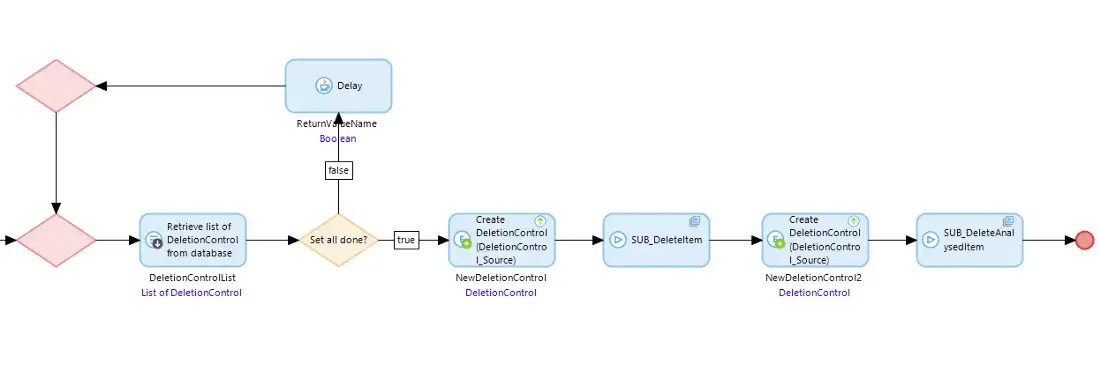
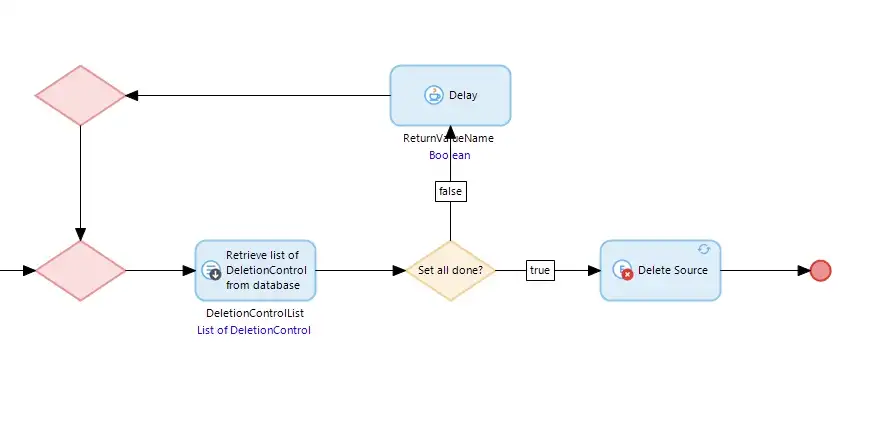
Similarly ‘SUB_DeleteItem’, when it has deleted all the items waits for Set Two to be completed and finally deletes the Source record, so completing the process. As the DocumentType and Document records are few in number we just delete them using the domain model ‘on deletion’ behavior.
How do they compare?
The test app also has a ‘Simple Delete Source’ button on the Source and this just deletes the Source directly and leaves the domain model to ensure the dependent objects are also deleted. So we can run either the Simple or the Smart Deletion for a set of test data. Also, the app has the ability to create a new set of test data, export a set of test data, and re-import a set of test data. In this way, the app will allow new sets to be created and it can export/import them so the Simple and Smart Deletion options can be used repeatedly with the same data.
I have a test data set which is included with the app in the resources directory called ‘Source-36e63c07–9a8a-4c94–8f87–0fbf9b7dd39f’, and this is the set used on my machine to compare the deletions. You can use this or make your own.
I ran the test app in Mendix 9.18.0 with it configured to access a local Postgres 10 database. Before testing each type of deletion I started the app from scratch. Then I imported the test dataset and ran the deletion five times over. I ignored the best and worst results of the five and averaged the remaining three timings.
So what was the outcome? The Simple Delete option took an average of 163.9 seconds. The Smart Delete option took an average of 29.4 seconds — less than a fifth of the elapsed time taken by the Simple Delete. Now if the user is waiting for the deletion to complete then this sounds like a worthwhile saving.
There are other ways to improve the user experience with this operation — for example, you could mark the Source as deleted by putting a boolean flag on the Source record and then having a separate periodic scheduled event process that deletes Source records and their dependents that are so marked. There is never only one solution to your problem.
Also, it should be appreciated that having multiple threads working hard for one user may have the effect of slowing down the app for other users so the needs of the precise use case and the effect of the solution should be fully understood and balanced.
Don’t forget that if you have a Production environment that is horizontally scaled, then the tasks in a Task Queue will be distributed across the available nodes in the cluster, which may give you additional time savings (though the scenario presented here is focussed on the database which is always a shared resource).
One more thing
As things stand we have a significant time saver for the user which we hope will improve their experience while using the app. But one thing has been missed.
In the Domain Model the associations between Item, ItemValue, ItemAttachment, ItemLink, AnaysedItem, AnalysedValue, and AnalysedAttachment still have the automatic deletion options configured. Now when using the Smart Delete option the automatic deletion of these Objects in the Domain Model does not actually delete anything because the target data has already been deleted. However, the Mendix Runtime will still need to look to see if there are any records to be deleted and that takes time.
So finally we can remove the automatic deletion options from the Domain Model and re-run the Smart Deletion to see what effect that has.
After making this change running the Smart Delete five times as before produced an average elapsed time of 10.0 seconds compared to 29.4 seconds. So we now have reduced the ‘regular’ elapsed time of 163 seconds down to 10 seconds. That sounds like a win to me, but be aware that deleting a Source will no longer cascade down the dependencies so if there are other places in the app where deletions have to be applied to this data, then you will need to engineer a solution for that too.
In summary
Using Task Queues can significantly improve elapsed time performance when judiciously applied to an appropriate use case. In this instance, the test results show a significant saving for the user.

Your mileage may vary
I probably don’t need to say this but the benefits of using this technique (for any type of process, not just large deletions), will vary greatly depending on the complexity of the operation being undertaken and the Domain Model, how much you have in terms of spare resources in your environment, and how complicated you want your model to be. Once again, I refer back to my comments in my previous blogs about keeping your code readable and maintainable.
Further, if two or more users delete Source records at the same time the queue resources will be shared and the saving for each may be less.
I have used a technique like this in a real production environment (that was pre-Mendix 9 so it used the ProcessQueue Marketplace module) and made performance gains that astonished me and delighted the Product Owner. So be sure to create a branch and try it out.
Happy queueing!