Pushing Mendix Performance Limits

As a low-code platform, Mendix is designed to run for all types of business at various ranges of size. This is one of the reasons for our node-based deployment. It allows you to choose the best level of processing power to support your application – not too much, not too little, but the one that’s just right.
This allows you to balance out performance versus cost. It also means you can start small and then begin to scale up your application as you gain more users.
What happens if your application really starts to take off though? If your user base jumps up and the number of transactions you have to handle increases exponentially? Can Mendix manage it?
High usage applications in Mendix; 100k concurrent users
The challenge is set!
Here at Mendix, we like to push our platform to the limits. We like to keep making things bigger, better, and bolder until they eventually break. Breaking is, after all, the best way of testing. In pursuit of this time-honored pastime, we asked ourselves: “How many concurrent users can we support? One thousand? Ten thousand? What about one hundred thousand?” To which we responded: “Let’s find out!”
What do we know?
We have customers around the world running their applications on the Mendix platform. Some are small apps running for a handful of users while some are truly enterprise-level applications operating for a vast number of users.
For example, PostNL processes over a million orders a day with their order management system, and the Dubai Municipality receives over one and a half million page views each month. So we know that Mendix applications can handle heavy workloads. The question remains, just how heavy can we make it?
What does our test look like?
A single test in this case is a user completing multiple transactions. We will aim to get one hundred thousand users completing transactions at the same time.
First, let’s define a transaction. What is a completed transaction? We are looking for a completed database commit action – something that adds new data to the database. It could be an entirely new record, or it could be a change to an existing record. The key thing is that the data in the database is permanently changed by the action.
Mendix is a huge platform that offers many different possibilities when building applications. This gave us a sea of options when choosing how to tackle this challenge. To keep it in line with an actual business situation, we chose a relatively simple task: an expenses claim.
The basic principle is that a user logs into the system and sends a series of simple expense claims. We chose to leave out file uploads at this point so the quantity of data wouldn’t prove to be a limiting factor. We just wanted to evaluate using basic insert and update transactions.
How we set up our Mendix performance limits test
App implementation
For our test application, we started with a basic template and added some very simple forms and functions to create an expense application. The frontend was kept to a minimum and no effort was made to optimize any images, CSS, or scripts. Our attention was mostly focused on creating the logic behind the scenes to enable our tests.
Test tool
To execute these tests, we utilized a tool we already used elsewhere within the business: Gatling. This tool is designed to load test platforms using scripts. Given that we already had some scripts created, and the experience necessary to change them, it seemed like a sensible option. This allowed us to create a test script that would perform the tasks laid out above at the scale we needed in order to reach the goal we were aiming for.
Infrastructure starting point
Go big or go home, right? The first thing we considered was requesting the largest custom node that our support team could provision. However, we wouldn’t be able to implement the level of logging and have the level of control we would need to make this test work. Our Mendix Cloud is designed to handle logging and metrics on your behalf and is easy to manage and deploy. It’s not intended for you to be able to add bespoke tracking and fiddle with config, so we needed an environment with more manual control in order to push the boundaries and break things!
So, we set up our first private instance on AWS EC2 and added some custom analytics and metrics gathering using Grafana and InfluxDB to track the performance of the systems. We also installed an async-profiler and YourKit to observe the runtime in greater detail directly. To keep things simple, and allow us to change things easily, we used a single node to host both the application and the database.
Executing our performance limits test
First run results
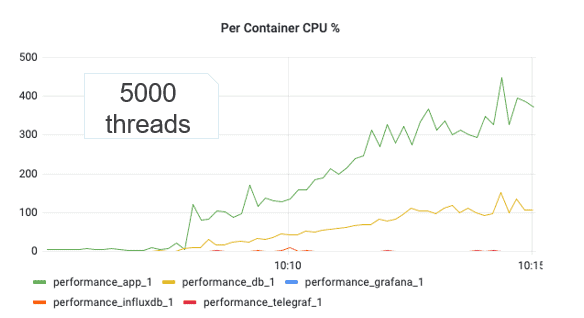
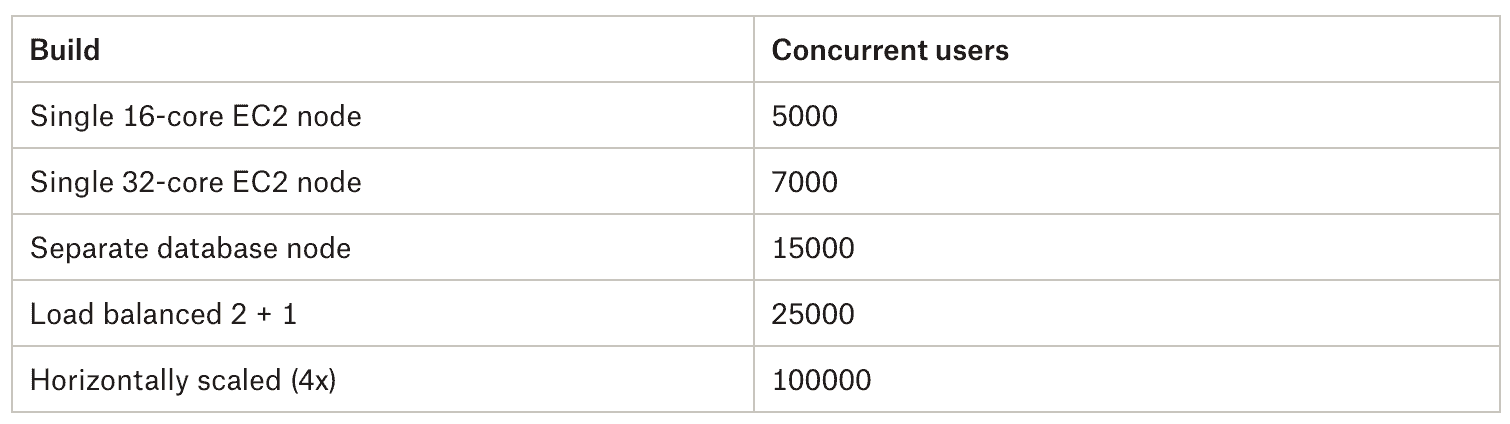
When we executed our first test on this server setup, we managed to achieve a respectable 5000 concurrent users. It was a good start, but it wasn’t where we wanted to be. We then began to iterate on our server setup to try and squeeze out as much performance as we could.
Iterations and improvements
The first change was to increase the size of our AWS EC 2 instance, where we doubled the size, and to make some changes to the Java settings and Database pools. This managed to get us to 7000 concurrent users and 180 expenses per second.
Next, we separated the database from the main instance and put it on a separate node entirely. We also worked with our internal spec-ops team to increase the size of our setup. This led to us increasing our transaction count again. Now we were achieving 15,000 concurrent users with a throughput of 373 expenses per second.
Over the course of these tests, we also noticed discrepancies in our test script in Gatling. Because of this, we made changes to the payload to more closely resemble the information submitted by the MxClient and made changes to the values that were being submitted to be a better fit for the expected values.
The next big jump we achieved was a matter of scaling out our instance. We switched to a horizontally scaled landscape using three application servers in front of one database server. This setup allowed us to reach 30,000 concurrent users with just over 700 transactions a second but we also noticed a common networking bottleneck preventing Gatling from increasing the load.
In order to get around the network bottleneck and to allow Gatling to provide more load, we switched to using a larger number of smaller Gatling instances. We started by repurposing one of our application nodes and created the setup below.
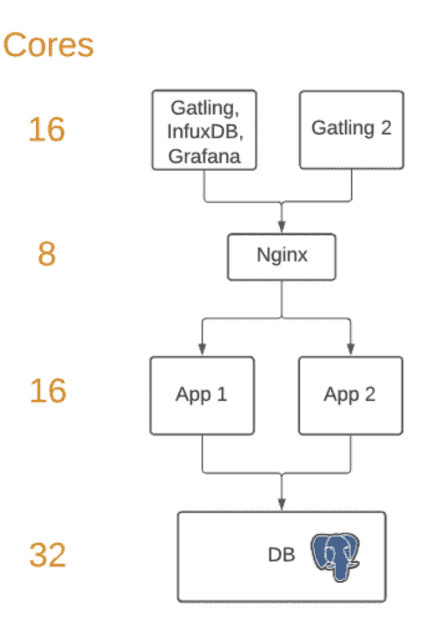
These changes got us to the point where we were successfully and stably enabling 25,000 concurrent users! The total count had dropped slightly, as you’d expect, from having three application servers but this was a setup we could scale to hit our target.
For the final push, we did just that. We scaled the setup to comfortably support a factor of four increase in processing power, arriving at a cluster with four large app nodes and a twice as large DB server. It seems like a lot, but a company expecting to handle the number of concurrent users we’re looking to achieve would need to expect infrastructure of this scale.
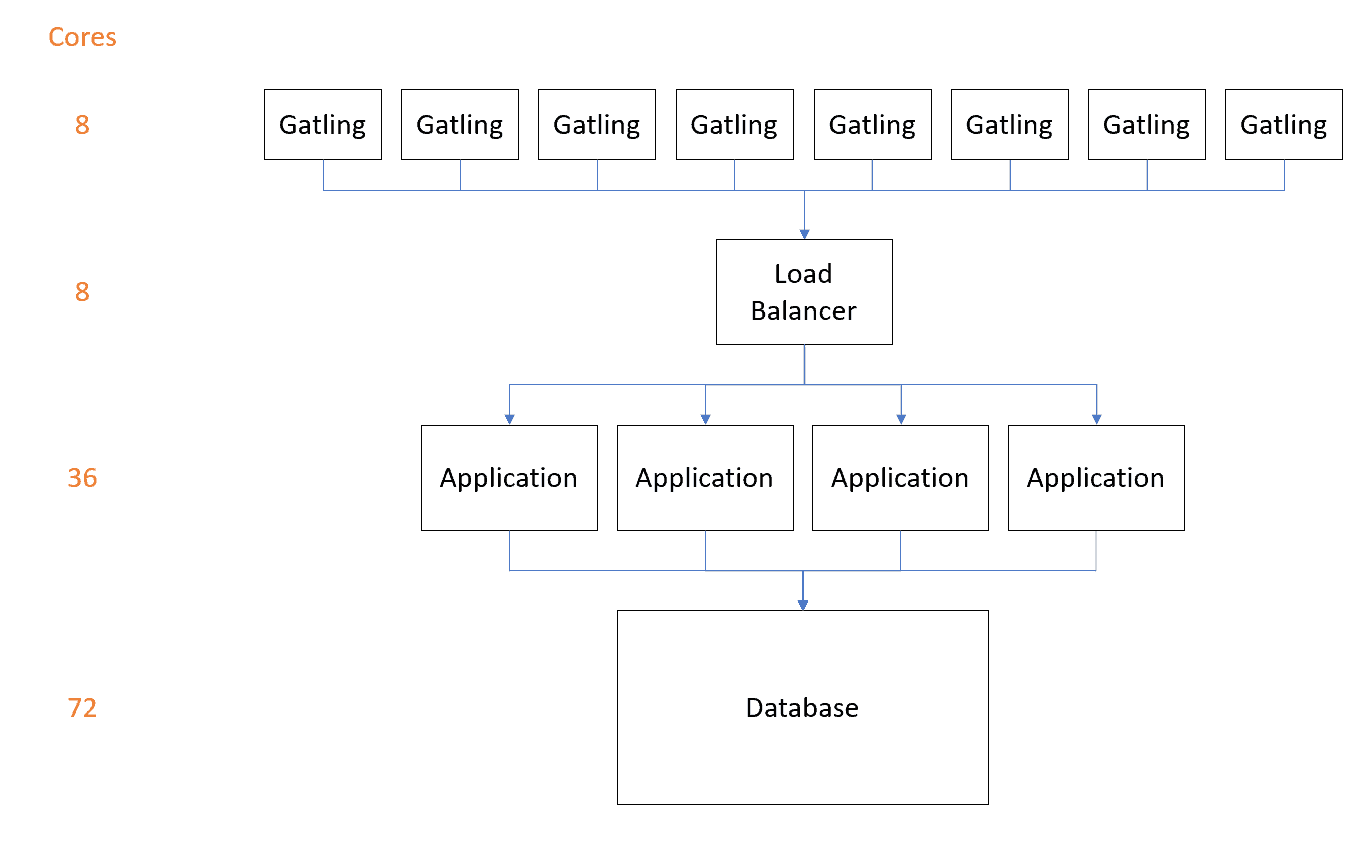
Once we had the four app servers, we managed to hit that magic 100K customers!
The takeaway
What we have proved is that the Mendix platform and runtime, and thus a Mendix application, is absolutely capable of handling this volume of concurrent users. The insights we have taken from this exercise regarding configuring and deploying servers have been shared with our cloud team and we’ll be looking to make improvements to our cloud infrastructure going forwards. Hopefully, we can help improve the already good base level of performance a standard Mendix node is capable of.
Coming up next time will be a more in-depth guide to the setups we created and the changes we made to achieve this phenomenal result.
