如上所述 在我们关于 OData 支持的博客文章中 Mendix,如果你想从应用程序中访问数据,OData 也很有用 R or RStudio。在这篇博文中,我将向您展示如何做到这一点。我还将针对不熟悉 R 的人给出一些如何使用 R 的简单示例。
什么是R?
R 是一种非常流行的开源统计分析编程语言,许多数据科学家都在使用它。您可以下载免费的开源版本,但您也可以在许多商业工具中找到 R 支持,包括 Microsoft Revolution R、Tibco Spitfire、Pivotal、Oracle 和 Tableau。R 的有趣之处在于您可以使用大量库。库的范围从数据处理算法到图形、报告到机器学习。
将 OData 加载到 R 中
为了将 OData 检索到 R 中,我们将使用两个包: 哈特 金益辉 XML。第一个包使您能够从网络读取数据,第二个包可用于解析 XML 文档。
通过使用这些包的小函数,您可以获取 OData 资源并将其转换为 R 数据。
dataset <- getODataResource(<url of the odata resource>,<username>,<password>)在开始之前我们需要指定我们需要的库。
library('httr')
library('XML')
library('dplyr')
library('lubridate')getODataResource 函数首先读取 OData 资源,并使用 Httr 包解析返回的 XML 文档。接下来,它确定属性的名称,获取值,并构建包含这些值的数据框。
getODataResource <- function(resourcePath,domain,usr,pwd){
url <- paste(domain, resourcePath,sep="")
# get the OData resource
response <- GET(url,authenticate(usr,pwd))
# parse xml docucument
responseContent <- content(response,type="text/xml")
# determine the names of the attributes
xmlNames <- xpathSApply(responseContent,
'//ns:entry[1]//m:properties[1]/d:*',xmlName,
namespaces = c(ns = "https://www.w3.org/2005/Atom",
m="https://schemas.microsoft.com/ado/2007/08/dataservices/metadata",
d="https://schemas.microsoft.com/ado/2007/08/dataservices"))
# determine all attribute values
properties <- xpathSApply(responseContent,'//m:properties/d:*',xmlValue)
# cast the attributes values into a data frame
propertiesDF <-
as.data.frame(matrix(properties,ncol=length(xmlNames),byrow=TRUE))
# set the column names
names(propertiesDF) <- xmlNames
return(propertiesDF)
}这是您需要检索的基本功能 Mendix OData 资源导入 R。在当前形式下,它不处理嵌套数据,例如,订单行嵌套在订单中的订单。它也不使用 OData 资源中包含的数据类型信息。相反,我们将使用一些 R 表达式手动指定数据类型,如下所示。
示例用例
这个例子 Mendix 应用程序有订单、客户和地址的资源。我们将在 R 中创建每个城市的订单数量概览。
首先,我们将定义如何连接到我们的 Mendix 应用程序。
domain <- "https://localhost:8080/"
username <- "demo_reporter"
password <- "goSfcsDj00"[/bash]
The following will load all the objects in the customers and address entities into R data frames.
[bash]customers <- getODataResource("odata/Orders/Customers()",domain,username,password)
addresses <- getODataResource("odata/Orders/Address()",domain,username,password)对于订单,我们只对 1 年 2014 月 XNUMX 日以来创建的订单感兴趣。我们可以在 R 中按订单日期进行过滤,但在 OData 资源 URL 上指定它可以避免从您的 Mendix 数据库,并将所有数据从 Mendix 运行到 R。
orders <- getODataResource(
"odata/Orders/Orders()/?$filter=OrderDate%20gt%20datetimeoffset'2014-01-01T00:00:00z'"
,domain,username,password)数据框包含所有 Mendix 对象,通过 OData 资源检索。订单的前五条记录如下所示:
orders[1:5,c("OrderNumber","Order_Customer","OrderDate")]## OrderNumber Order_Customer OrderDate
## 1 1 2533274790395905 2015-01-18T10:32:00.000Z
## 2 2 2533274790395906 2014-01-30T07:01:00.000Z
## 3 3 2533274790395907 2014-04-16T13:15:00.000Z
## 4 4 2533274790395908 2014-09-19T07:52:00.000Z
## 5 5 2533274790395909 2015-01-14T07:28:00.000Z现在我们有了数据,我们需要确保使用正确的数据类型。 Mendix ID 使用 long 实现 Mendix。在 R 中,可以使用双精度数。
customers$DateOfBirth <- ymd_hms(customers$DateOfBirth)
customers$ID <- as.double(customers$ID)
customers$Billing_Address <- as.double(customers$Billing_Address)
customers$Delivery_Address <- as.double(customers$Delivery_Address)
addresses$ID <- as.double(addresses$ID)
orders$ID <- as.double(orders$ID)
orders$Order_Customer <- as.double(orders$Order_Customer)
# for easy access, create separate columns with date and date time
orders$OrderDateTime <- ymd_hms(orders$OrderDate)
orders$OrderDate <- ymd(format(ymd_hms(orders$OrderDate),"%Y-%m-%d"))接下来我们将使用 dplyr 库来处理收到的数据。Dplyr 可让您过滤数据、添加新列、选择某些列以及对行进行排序,这与您在常规数据库中使用 SQL 执行的操作非常相似。
以下 dplyr 表达式连接客户、地址和订单数据框。
customerOrders <- customers %>%
rename(CustomerID=ID) %>%
left_join(addresses, by=c("Delivery_Address"="ID")) %>%
select(CustomerID,Firstname,Lastname,City,Country) %>%
left_join(orders, by=c("CustomerID"="Order_Customer")) %>%
select(Firstname,Lastname,City,Country,OrderNumber)该数据框的前行如下所示:
customerOrders[1:5,]## Firstname Lastname City Country OrderNumber
## 1 Ivan Freeman New Orleans US 1
## 2 Ivan Freeman New Orleans US 499
## 3 Anthony Robinson Brighton US 2
## 4 Anthony Robinson Brighton US 500
## 5 Kaden Griffith Bridgeport US 3现在我们可以按如下方式计算每个城市的订单数量:
cityOrderCount <- customerOrders %>%
group_by(City) %>%
summarize(OrderCount = n()) %>%
arrange(desc(OrderCount))结果:
cityOrderCount[1:5,]## Source: local data frame [5 x 2]
##
## City OrderCount
## 1 New York 28
## 2 Philadelphia 16
## 3 Chicago 15
## 4 Miami 12
## 5 Baltimore 10创建图表
以下示例使用 ggplot2 创建图形。您也可以使用其他库来绘制图形,但 ggplot2 是最受欢迎的库之一。
我们将从一个简单的 bart 图开始,绘制每月的订单数量。
library('ggplot2')
# Determine first day of month for every order, count number of orders per month
orderCount <- orders %>%
# Determine date of first day of the month, so ggplot understands it's a date
mutate(OrderMonth = ymd(format(OrderDate,"%Y-%m-01"))) %>%
group_by(OrderMonth) %>%
summarize(noOfOrders = n())
# generate barchart to display number of orders per month
ggplot() +
geom_bar(data=orderCount,aes(x=OrderMonth,y=noOfOrders), stat="identity") +
xlab("Month") +
ylab("Number of orders") +
ggtitle("Orders per month")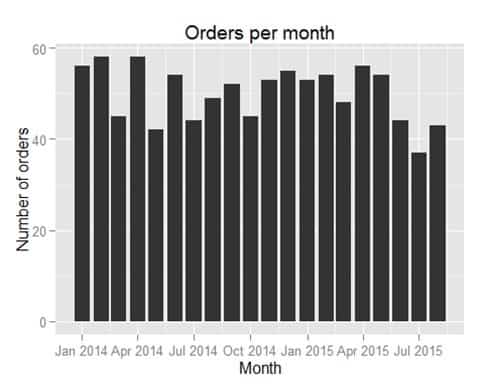
接下来,我们想看看订单是在一周内何时下达的。首先,我们需要数据集,其中包含每笔订单的星期几和一天中的小时数。
ordersPerWeekHour <- orders %>%
mutate(DayOfWeek = wday(OrderDate)) %>%
mutate(HourOfDay = hour(OrderDateTime)) %>%
group_by(DayOfWeek,HourOfDay) %>%
summarize(noOfOrders = n())现在对于实际的图表,我们可以使用 瓦片平面 显示每天每小时的订单数量。我们将日期放在 x 轴上,将小时放在 y 轴上,并使用订单数量来确定显示的颜色。
ggplot(ordersPerWeekHour, aes(x=DayOfWeek,y=HourOfDay))+
geom_tile(aes(fill=noOfOrders)) +
scale_fill_gradient(low="green", high="red") +
scale_x_continuous(breaks=1:7,labels=c("Sun","Mon","Tues","Wed","Thurs","Fri","Sat")) +
scale_y_continuous(breaks=0:24) +
labs(x="Day", y="Hour")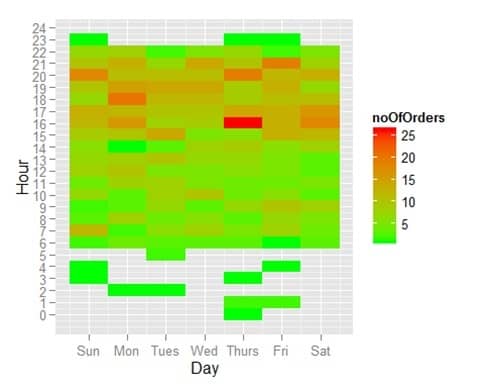
现在您可以轻松看到,大多数订单都是在 16:00 到 22:00 之间下达的,均匀分布在一周的所有日子里。
使用 R 生成报告
R 有一些有趣的报告功能。使用 降价,您可以直接从 R 报告生成 HTML、Word、PDF 甚至幻灯片。
这篇博文实际上是用 rmarkdown 编写的,生成了一个 MS-Word 文档。要用我的最新数据更新 Word 文档 Mendix 应用程序,我只需要重新运行 rmarkdown 脚本。
使用 Rmarkdown 最简单的方法是使用 RStudio 的内置功能。或者,您可以使用一些 R 代码生成 Rmarkdown 报告,而无需使用 RStudio:
library(knitr) # required for knitting from rmd to md
require(rmarkdown) # required for md to html
setwd('<location of your rmarkdown file>')
render("<name of the rmarkdown script>", "all")结语
OData 功能 Mendix 为……开辟了很多可能性 Mendix 用户。R 是一款功能强大的统计分析和数据报告工具。使用 OData Mendix 用户现在可以轻松受益于所有这些设施。